Glossary
View this page on GitHub
General Links and Resources
- Thomas Yeh: https://www.byhand.ai substack and online courses
- you are subscribed to his/their Substack newsletter
- He has a free Agentic AI intro course: https://www.byhand.ai/p/introduction-to-agentic-ai
- Check out the course you have joined here: https://community.genai.works/
- L402.org: AI Agent payment protocol (?)
- https://docs.nvidia.com/nemo-framework/index.html: NVIDIA Nemo Framework. From DataExpert.io course. Use to implement Guardrails?
– A –
- A2A: Agent to Agent interactions/transactions - example: A research agent pays a summarization agent
- related:
- H2A: Human to Agent - example: User pays ChatGPT or invokes a tool
- A2H: Agent-to-Human - example: Agent pays a contractor or requests approval
- A2S: Agent-to-Service - example: Agent pays an API or SaaS endpoint
- B2B / P2P: traditional payments (non autonomous)
- A2A systems require:
- Machine-verifiable identity
- Programmatic authorization
- Instant or near-instant settlement
- Micropayments
- Deterministic execution
- Cryptographic guarantees
- related:
- Agentic AI: Yeh Course - Agentic AI takes artificial intelligence beyond simple prompt-based responses. Unlike traditional models, agents can observe, reflect, use tools, plan ahead, and even collaborate—just like a human problem solver
- Agentic AI - Payment Protocols: (relatively) early protocols addressing different types AI Agent payment use cases. Listed below are major protocol alternatives:
- Agentic Commerce Protocol (ACP): An open commerce standard for AI agents to complete purchases on behalf of users, focused on checkout and payment interactions using existing payment rails (credit/debit cards, tokenization)
- Agent Payments Protocol (AP2): An open standard for secure, interoperable agent-initiated payments, focused on authorization, trust, and auditability of payments initiated by AI agents. AP2 uses cryptographically signed “mandates” to ensure user intent and accountability for transactions
- x402: Internet-Native Payments Standard: An HTTP-native payment protocol that revives HTTP 402 (“Payment Required”) to enable autonomous payments between clients/agents and services. When a service requires payment, it responds with 402 and machine-readable payment instructions; the client pays and retries
- Universal Commerce Protocol (UCP): An emerging standard. A broader open commerce standard announced by Google and partners (2026) designed to unify multiple protocols across discovery → purchase → post-purchase, aimed at interoperability between agents and commerce endpoints. It complements AP2, ACP, A2A, and MCP rather than directly replacing them
- See: so ChatGPT Response
- AI Engineering: process of building applications leveraging readily available models
- activation function: activation functions prevent models from grounding neural network models down to linear models - ie. they introduce non linear dynamics (DA: otherwise the model just defaults to a weighted sum plus bias expression [?])
- ASR: Automatic Speech Recognition
– B –
- Backpropagation: DA | a training approach to iteratively adjust weights and bias values using an error correction algorithm such as gradient descent
– C –
- Chain of Thought (COT): explicitly asking the model to think step by step (“think step by step”, “explain your decision”)
- Chaining: breaking down prompts or model interactions into serial steps (e.g. as opposed to one encompassing prompt)
- Completion: the output of an LLM that is result of processing a prompt (e.g.
Go is...) with a completion ofa programming language... - Context Window: how big your prompt can be that is input to the model
- Most models have limits of ~2000 tokens
- Cosine Similarity: From ChatGPT Cosine Similarity is a measure of similarity between two vectors in a high-dimensional space, commonly used in LLMs for text embeddings and semantic search. It calculates the cosine of the angle between two vectors, where 1 means identical, 0 means unrelated, and -1 means completely opposite
| Concept | Description | Operator/Syntax | Notes |
|---|---|---|---|
| Cosine Similarity | A measure of how one vector’s direction is similar to another vector’s direction. In Postgres pgvector you get this by subtracting the Cosine Distance from 1 |
pgvector: 1 - (A <=> B) |
Values: -1 to 1 (higher value means most similar) |
| Cosine Distance | Also a measure of how one vector differs from another in terms of its direction | pgvector: A <=> B |
Values: 0 to 2 (lower value means most similar) |
– D –
- dspy:
dspy(short for Declarative Self-Improving Language Models) is an open-source Python framework for building self-improving LLM applications.- It allows engineers to define AI tasks declaratively and then automatically optimize, test, and refine the prompts, parameters, and reasoning strategies that an LLM uses to complete those tasks
- High-Level dspy Workflow
- You define a task module/signature.
- You provide a dataset of (input → correct output) examples.
- You choose an optimizer (MIPRO, BootstrapFewShot, COPRO, etc.).
dspytests many versions of system prompts internally.dspyselects the best-performing prompt/module configuration.- You freeze/export the optimized program for production use.
– E –
- embeddings: vector that aim to capture the meanings of the orginal text (from which the embedding was calculated)
- From ChatGPT An embedding is the dense vector form that represents a concept in a model’s “understanding space"
- embeddings encode meaning rather than direct word identity.
- From ChatGPT An embedding is the dense vector form that represents a concept in a model’s “understanding space"
🧠 3. Summary of Sparse Vector vs. Embedding
| Feature | Sparse Vector | Dense Vector / Embedding |
|---|---|---|
| Size | = vocabulary size (can be 10k–1M+) | Typically 256–4096 |
| Meaning of each position | Specific word or feature | Learned, abstract dimension |
| Zeros | Mostly zeros | Mostly non-zero |
| Captures semantics? | No | Yes |
| Memory efficiency | Poor | High |
| Used by | TF-IDF, one-hot, bag-of-words | Neural nets, LLMs, embeddings |
In short:
Sparse vectors explicitly reference the vocabulary. Dense vectors / embeddings encode the vocabulary’s meaning in a continuous, compact space.
- entropy: a measure of uncertainty or randomness in predicting the next token (word, subword, or character) in a sequence. It quantifies how confident or uncertain a model is about its predictions
- epoch: an epoch one complete pass through the entire training dataset during the learning process of a machine learning model. During an epoch, every sample in the dataset is typically used once to update the model’s parameters
- (model) evaluation: see table below for breakdown of using other models to evaluate an LLMs performance
| Evaluation Need | Popular Model Choices |
|---|---|
| General output scoring (quality, coherence) | GPT-4, GPT-4o, Claude Opus |
| Safety / Jailbreak detection | Llama Guard, Claude, GPT-4 |
| RAG grounding & relevance | GPT-4 + RAGAS |
| Summarization evaluation | GPT-4, Claude, ROUGE + judge LLM |
| Semantic similarity scoring | BERTScore, SBERT |
| Internal enterprise evals | Llama 3 70B, Mistral, Qwen2 |
| Preference ranking model training | Reward models (OpenAI, Anthropic) |
– F –
- Few Shot Prompts: From PredictionGuard docs When your task is slightly more complicated or requires a few more leaps in reasoning to generate an appropriate response, you can turn to few shot prompting (aka in context learning). In few shot prompting, a small number of gold standard demonstrations are integrated into the prompt
- See also Zero Shot Prompt
- Foundation Models: From ChagGPT large-scale AI models trained on vast amounts of diverse data that serve as a base for various downstream tasks. These models, such as GPT, BERT, and DALL·E, are typically trained using self-supervised learning and can be fine-tuned for specific applications like chatbots, image generation, or medical diagnosis. Their broad generalization capabilities make them foundational for multiple AI applications across industries
- Language Models > Large Language Models > Foundation Models
- e.g. Gemini, GPT-4V
- the AI Engineering book uses the term
Foundation Modelto refer to both Large Language Models and Large Multimodal Models - Foundation Models should be capable of a wide range of tasks
– G –
- Non-Generative Tasks: From ChatGPT problems where the model does not generate new content, but rather classifies, recognizes, retrieves, or predicts structured outputs based on existing data. Unlike generative AI, which creates novel text, images, or other media, non-generative AI primarily analyzes and processes information
- Generative Models: models that generate open ended output
- Gradient: DA: a gradient is an adjustment to the weights and bias values assigned to neurons that will lower the error (or loss). It is computed using partial derivatives of the loss function with respect to each weight
- Gradients measure how much a weight affects the error
- Gradient descent updates weights in the direction that reduces error (DA: is this why it’s called Gradient Descent?)
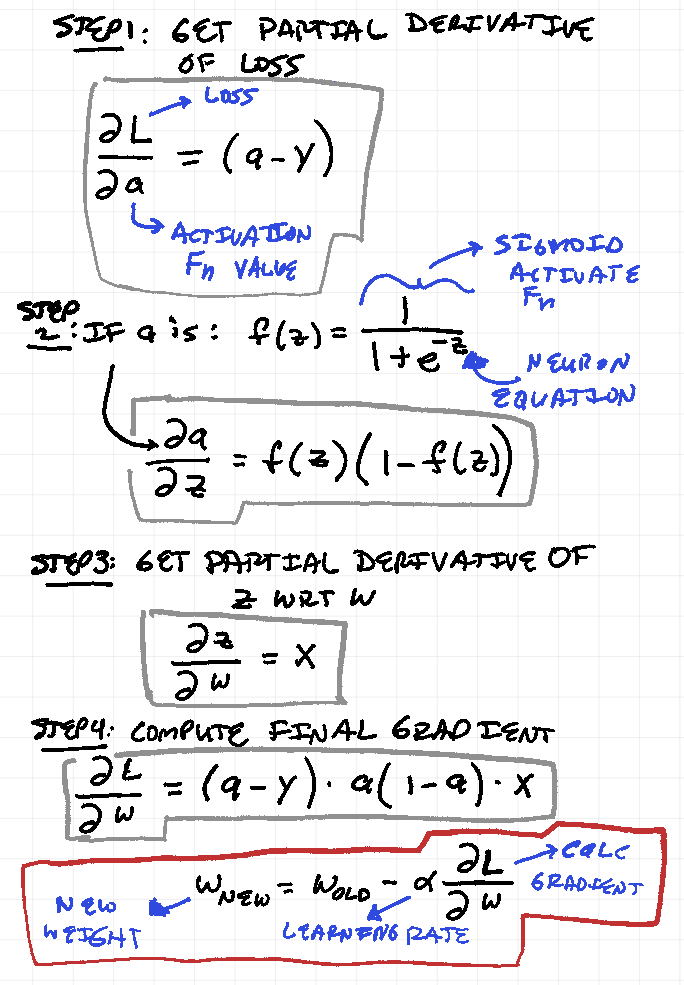
– H –
- hallucinations: refer to instances where an LLM model generates false, misleading, or nonsensical information that is not grounded in factual data or its training knowledge
- Factuality: using another model (or other methods?) check the accuracy of LLM output
- human-in-the-loop: humans involved in AI driven decision making processes
– I –
-
In-context Learning:
-
Teaching models what to do via prompts
- see “shots” as examples provided to an LLM
– J –
- jailbreaking: from ChatGPT Jailbreaking is the act of intentionally manipulating a large language model (LLM) into bypassing its built-in safety constraints, content filters, or policy restrictions so that it produces outputs it is not supposed to generate.
– L –
- Language Model: language models encode statistical information about one or more languages
- Language models are completion engines. Completions are essentially predictions based on probablities and not guaranteed to be accurate
- For example for the sentence:
My favorite color is ______, the model would estimate the wordbluewould complete the sentence with a higher priority thancar. - Two types of Language Models
- Masked Language Model: is trained o predict missing tokens anywhere in a sequence, using context from both before and after the missing tokens. Used for tasks such as sentiment analysis and text classification
- Autoregressive Language Model: models trained to predict the next token in a sequence using only the preceeding tokens
- LangChain: LangChain is an open-source framework for building applications powered by Large Language Models (LLMs). Instead of being a single model or API, LangChain gives developers a toolkit for chaining together LLM calls, external data sources, tools, and custom logic to create more advanced AI systems
- Latency Metrics: high level metrics to assess AI model latency
- TTFT: Time to First Token
- TPOT: Time per Output Token
- Total Latency: assume this is the time from inbound request to the fulfilled completion
- LLM: Large Language Models | From ChagGPT Large Language Models (LLMs) are AI models trained on vast amounts of text data to understand, generate, and manipulate human language. They leverage deep learning architectures, particularly transformers, to perform tasks like text generation, translation, summarization, and coding
- LLMs are configured/trained to perform the task of text completion
- Examples of LLMs
- GPT-4, GPT-3.5 (OpenAI) – General-purpose text generation.
- Claude (Anthropic) – AI assistant with ethical alignment.
- Llama 2 (Meta) – Open-source conversational AI.
- PaLM 2 (Google) – Used in Bard and other applications.
- Why Are LLMs Important? LLMs power chatbots (ChatGPT, Bard), virtual assistants, search engines, coding tools (Copilot), and AI agents. They are revolutionizing industries by automating and enhancing human-computer interactions
- Strengths & Weaknesses: LLMs are typically good at this type of “autocomplete on steroids” but not necessarily good at data analysis or data analytics
- An Approach: use an LLM to generate the code to solve a data analysis question, execute that code, and then return the output to the LLM user
- LLM Judge or LLM Critic: using another model to judge the factuality (or accuracy?) of an LLM
- LVM: Large Vision Models | These multimodal models are designed for inference using text and images (e.g.
llava-1.5-7b-hf)
– M –
- MCP: From ChatGPT Model Context Protocol
- MCP is an open standard / protocol introduced by Anthropic in November 2024.
- Its purpose is to provide a unified, standardized way for large language models (LLMs) or AI systems to connect with external data sources, tools, and services (e.g., databases, file-systems, APIs, other AI agents).
- It’s often described metaphorically as a “USB-C port for AI apps” — i.e., a single common interface through which many different kinds of tools/data can plug into AI workflows.
- MCP is fundamentally a tooling and data-access protocol, not a model-serving protocol
- An MCP server exposes:
- tools (functions the client/LLM can call)
- resources (documents, URLs, databases)
- prompts (template suggestions)
- context extensions (metadata, workspace awareness)
- memorization rate: From ChatGPT he memorization rate refers to the proportion of training data that the model has directly memorized and can reproduce verbatim or nearly verbatim during inference
- “A higher memorization rate indicates the model has overfit or retained specific examples rather than generalizing patterns; a lower rate suggests better abstraction and generalization”
- middleware: from ChatGPT Middleware is the layer that manages communication, data flow, validation, orchestration, and integrations between AI models and the application so developers don’t have to handle those details directly
- middleware can handle tasks such as:
- Authentication and API key management
- Caching and deduplication
- Error normalization
- Event or job-queue handoff (e.g., sending work to worker dynos)
- Input normalization (cleaning, chunking, embedding text, shaping JSON)
- Integration with storage (vector DBs, Supabase, Redis, Postgres)
- Logging and telemetry
- Model routing (deciding which LLM, embedding model, or tool to call)
- Rate-limit handling and retries
- Response post-processing (formatting, schema validation, safety filters)
- Tool/function call orchestration
- middleware can handle tasks such as:
- Models as a Service: leveraging models trained and deployed by third parties to drive AI applications
- Multi Modal: models or implementations (?) that handle or generate multiple types of content: text, images, video. (As opposed to just text which I assume ChatGPT is). Most enterprise use is still currently LLMs focused on text.
- assume Foundation Models are multi modal models as they can (should) handle non text data
– N –
- Natural Language Supervision: e.g. using combinations of images and text on the web to automate supervision (as opposed to manual supervision). Way to scale model training
– O –
- open weights: From ChatGPT In the context of AI and AI engineering, the term “open weights” refers to machine learning models whose trained parameters (weights) are publicly released, allowing anyone to use, inspect, fine-tune, or deploy the model — even if the underlying architecture or training data might not be fully open.
- weights can be inspected and tweaked and inference can be generated/computed locally - use open LLM models
– P –
- parameter: a variable in a model that is updated via training, a large model has a relatively high number of parameters
- large models should be trained on large amounts of data so that compute resources can be use parameters optimally
- Prompting: is the process of providing a partial, usually text, input to a model
- Prompt Engineering: the process of crafting an instruction that gets a model to generate a desired outcome
- is the easiest and most common model adaptation technique
- guides a model’s behavior without adjusting the model weights (finetuning adjust model weights [?])
- separate prompts from code; assign metadata to prompts; there are tools/frameworks you can use (e.g.
Dotprompt)
- prompt injections: prompt injection is the manipulation of an AI system by inserting crafted text that overrides or subverts the system’s intended instructions, either directly in user input or indirectly through external data sources
- prompt optimization: from ChatGPT Prompt optimization is the systematic process of designing, refining, and evaluating prompts to improve the accuracy, consistency, safety, and efficiency of an AI model’s responses. It involves intentionally structuring prompts—using wording, formatting, examples, constraints, and context—to maximize the model’s performance for a specific task or workflow
- LLMs are probabilistic models: their output depends heavily on how the prompt is written. Small changes in phrasing, ordering, examples, or metadata can meaningfully change:
- accuracy
- reasoning quality
- hallucination rate
- tool-calling behavior
- computation cost (tokens, latency)
- safety alignment
- LLMs are probabilistic models: their output depends heavily on how the prompt is written. Small changes in phrasing, ordering, examples, or metadata can meaningfully change:
- auto prompt optimization: the system (not a human) iteratively rewrites and tests prompts until it finds the versions that produce the most accurate, reliable, or cost-efficient outputs
- automatically and test thousands of prompt variations to optimize performance
- Prompt Templating: structuring user prompt responses for input to a model
- See also: docs entry
- Why?: e.g. adhere to company policy, take into account past successful prompts
- Simple template:
- Context: …. (e.g. here you can inject your context)
- Question: …. (insert the user’s question here)
- Context:
- Lots of Context Data: most LLMs do not perform well ingesting and accommodating large amount of context data
- Approach:
- loop over the context data (tokens / words) and split into chunks with some overlapping number of characters
- vectorize those chunks
- Approach:
- Lots of Context Data: most LLMs do not perform well ingesting and accommodating large amount of context data
- system vs user prompt: some model APIs allow the prompt to be split in a system prompt and user prompt
- system: think about this as the task description
- user: think about this as the task
– R –
- Reranker Models: These models are designed for semantically ranking text. Unlike embedding models, rerankers take a query and document (or passage) as input and directly output a similarity score. The output relevance score can be converted to a float value in the range [0,1] using a sigmoid function
- Retrieval-Augmented Generation (RAG): From ChatGPT Retrieval-Augmented Generation (RAG) is a technique that enhances Large Language Models (LLMs) by incorporating external knowledge retrieval during text generation. Instead of relying solely on pre-trained knowledge, RAG dynamically fetches relevant data from external sources like databases, documents, or APIs to improve accuracy and reduce hallucinations
- How RAG Works
- Retrieval Step (“Retriever”) – The system queries an external knowledge base (e.g., a vector database, Wikipedia, PDFs, APIs) to find relevant documents.
* Retrievers have two main functions: indexing and querying
- Retrieval works by ranking documents (by calculating a retrieval score?) based on their relevance to a given query
- Augmentation Step – The retrieved information is injected into the LLM’s context.
- Generation Step – The LLM generates responses based on both retrieved and pre-trained knowledge.
- Retrieval Step (“Retriever”) – The system queries an external knowledge base (e.g., a vector database, Wikipedia, PDFs, APIs) to find relevant documents.
* Retrievers have two main functions: indexing and querying
- Misconception: it’s assume that for Chatbots to “know” about the company’s proceses or landscape that that is achieved through model finetuning. This is not correct. That Chatbot “understanding” is done via RAG (see overall process above)
- Naive RAG vs. Advanced RAG Techniques: we do naive RAG above but there are more adanced techniques that can be used (e.g. hierarchical searches, use an LLM to improve the prompt query prior to execution)
- Google search “Advanced RAG”
- How RAG Works
- Retreival Optimizatio:
- ROUGE: from ChatGPT ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a family of metrics used to evaluate how well an LLM-generated summary matches one or more reference summaries. It does this by measuring overlap between the model’s output and the reference text
- In AI Engineering and LLM evaluation, ROUGE is primarily used for:
- Summarization tasks
- Text generation quality checks
- Comparing models or prompt variants
- In AI Engineering and LLM evaluation, ROUGE is primarily used for:
– S –
- self-supervision: Language Models can be trained using self-supervision (most other models require supervision)
- labels are inferred by the input data
- Sigmoid Function: The sigmoid function is a mathematical function that maps any input x to a value between 0 and 1, making it useful for probability estimation in machine learning, including LLMs (Large Language Models)
- Logistic Regression: Used in binary classification tasks to predict probabilities.
- Attention Mechanisms: Helps normalize weights in transformer models.
- Output Activation: Used in tasks requiring binary probabilities, like sentiment analysis or text classification
– T –
- telemetry: from ChatGPT: the automatic collection, transmission, and analysis of operational data about your AI system’s behavior
- Telemetry typically includes:
- Cache hit/miss rates
- Error rates (timeouts, rate limits, schema violations)
- Event logs (what steps executed, where failures occurred)
- Latency (how long each LLM or API call takes)
- Model usage metrics (tokens used, model/cost per request)
- Queue depth (if using a job engine like Asynq, RQ, Celery)
- System resource usage (CPU, memory, disk, container health)
- Throughput (requests per second / jobs processed)
- Telemetry typically includes:
- token: the basic unit of language models. A token can be a character, word, or part of a word
- TFIDF algorthm: Term Frequency-Inverse Document Frequency - an algorthm that broadly measures the importance of a term in a corpus
- From ChatGPT: TF-IDF is a statistical measure that highlights how uniquely significant a term is in a document within a corpus — a foundational concept that paved the way for modern embedding and vector-based retrieval used in LLMs
⚙️ How it works
-
TF (Term Frequency) — how often a word appears in a single document $TF(t,d) = \frac{\text{count of term }t\text{ in document }d}{\text{total terms in }d}$
-
IDF (Inverse Document Frequency) — how rare the word is across all documents $IDF(t) = \log\left(\frac{\text{total number of documents}}{\text{number of documents containing }t}\right)$
-
TF-IDF = TF × IDF Words frequent in one document but rare across others get high scores, meaning they’re more informative for that document.
-
tokenization: decomposing an original text into tokens
- For GTP-4 the average token 3/4 of a word. 100 tokens typically represents 75 words
-
Transformer Architecture: From ChatGPT a neural network design that leverages self-attention mechanisms to process input data in parallel, rather than sequentially. This architecture forms the backbone of many state-of-the-art models in natural language processing and beyond, including BERT and GPT
– V –
- Vector Representation: also called an embedding; allows the model execution to do
semantic searchover chunks data (e.g. context tokens / data)- Why?: the model execution can then use the numerical vector representation of a context chunk and compare it to a user question and associate buckets on text together with respect to meaning
- https://lancedb.com: hosted vector database
- Cosine Similarity: From ChatGPT Cosine Similarity is a measure of similarity between two vectors in a high-dimensional space, commonly used in LLMs for text embeddings and semantic search. It calculates the cosine of the angle between two vectors, where 1 means identical, 0 means unrelated, and -1 means completely opposite
- Dense vs. Sparse: a
sparse vectoris on in which most values are 0. This implies a specific meaning with little semantic (?) connection to other words. Adense vectorhas all/mostly non-zero values. The vector values are leaned so they represent semantic meaning - vocabulary: the set of all tokens a language model can work on
– X –
x402Protocol: HTTP native protocol enabling autonomous payments between parties, specifically Agents.- x402 serves as a transport and authorization layer
- x402 answers: How do agents ask for, authorize, and prove payment?. It is the “Authorization & negotiation glue” between agents and payment rails
- go SDK:
go get github.com/coinbase/x402/go
- See: so ChatGPT Response
- x402 serves as a transport and authorization layer
– Z –
- Zero-Shot Prompt: a query or instruction given to a Large Language Model (LLM) without providing any examples or prior context. The model relies entirely on its pre-trained knowledge to generate a response
- From PredictionGuard docs: One of the easiest ways to leverage the above prompt structure is to describe a task (e.g., sentiment analysis), provide a single piece of data as context, and then provide a single output indicator
- See also Few Shot Prompts
View this page on GitHub